
This article introduces incremental garbage collection (GC) which has been introduced in Ruby 2.2. We call this algorithm RincGC. RincGC achieves short GC pause times compared to Ruby 2.1.
About the Author: Koichi Sasada works for Heroku along with Nobu and Matz on C Ruby core. Previously he wrote YARV Ruby's virtual machine, and he introduced generational GC (RgenGC) to Ruby 2.1. Koichi wrote incremental GC for Ruby 2.2 and authored this paper.
Background
Ruby uses GC to collect unused objects automatically. Thanks to GC, Ruby programmers do not need to release objects manually, and do not need to worry about bugs from object releasing.
The first version of Ruby already has a GC using mark and sweep (M&S) algorithm. M&S is one of the most simple GC algorithms which consists of two phases:
(1) Mark: traverse all living objects and mark as "living object". (2) Sweep: garbage collect unmarked objects as they are unused.
M&S is based on the premise that traversable objects from living objects are living objects. The M&S algorithm is simple and it works well.
Fig: Mark & sweep GC algorithm

This simple and effective algorithm (and a conservative GC technique) allows C-extension writers to write extensions easily. As a result, Ruby gained many useful extension libraries. However, because of this GC algorithm, it is difficult to employ moving GC algorithms such as compaction and copying.
Today, writing C-extension libraries is not as important because we can use FFI (foreign function interface). However, in the beginning, having many extension libraries and providing many features through C-extensions was a big advantage and made the Ruby interpreter more popular.
While M&S algorithm is simple and works well, there are several problems. The most important concerns are "throughput" and "pause time". GC slows down your Ruby program because of GC overhead. In other words, low throughput increases total execution time of your application. Each GC stops your Ruby application. Long pause time affects UI/UX on interactive web applications.
Ruby 2.1 introduced generational garbage collection to overcome "throughput" issue. Generational GC divides a heap space into several spaces for several generations (in Ruby's case, we divide heap space into two: one "young" and one "old" space). Newly created objects are located in the young space and labeled as "young object". After surviving several GCs (3 for Ruby 2.2), young objects will be promoted to "old objects" and located in the "old space". In object oriented programming, we know that most objects die young. Because of this we only need to run GC on the “young space”. If there is not enough space in the young space to create new objects, then we run GC on the “old space”. We call "Minor GC" when GC runs only in the young space. We call "Major GC" for GC that runs in both young and old spaces. We implemented generational GC algorithm with some customization and we call our GC algorithm and implementation as "RGenGC".
RGenGC improves GC throughput dramatically because minor GC is very fast. However, major GC must pause for a long time and is equivalent to pause time in Ruby 2.0 and earlier. Most of GC are minor GC, but a few major GC may stop your ruby application for a long time.
 Fig: Major GC and minor GC pause time
Fig: Major GC and minor GC pause time
To solve long pause time issue, incremental GC algorithm is a well known GC algorithm to solve it.
Basic idea of incremental garbage collection
Incremental GC algorithm splits a GC execution process into several fine-grained processes and interleaves GC processes and Ruby processes. Instead of one long pause, incremental garbage collection will issue many shorter pauses over a period of time. The total pause time is the same (or a bit longer because of overhead to use incremental GC), but each individual pause is much shorter. This allows the performance to be much more consistent.
Ruby 1.9.3 introduced a "lazy sweep" GC which reduces pause time in the sweeping phase. The idea of lazy sweep is to run sweeping phase not at once, but step by step. Lazy sweep reduces individual sweep pause times and is half of the incremental GC algorithm. Now, we need to make major GC marking phase incrementally.
Let us introduce three terminology to explain incremental marking: "white object" which is not marked objects "grey object" which is marked, but it may have a reference to white objects "black object" which is marked, but does not point any white object.
With these three colors, we can explain mark and sweep algorithm like that:
(1) All existing objects are marked as white (2) Clearly living objects such as objects on the stack marked Grey. (3) Pick one grey object, visit each object it references and color it grey. Change the color of the original object to black. Repeat until there are no grey objects left only black and white. (4) Collect white objects because all living objects are colored black.
To make this process incremental, we must make step (3) incremental. To do this, pick some grey objects and mark the objects they reference grey, and back to Ruby execution, and continue incremental marking phase, again and again.
 Fig: normal marking (STW: stop the world) vs. incremental marking
Fig: normal marking (STW: stop the world) vs. incremental marking
There is one problem to incremental marking. Black objects can refer white objects while Ruby executes. This is a problem since the definition of the "black object" states that it has no reference to white objects. To prevent such case, we need to use "write-barrier" to detect a creation of such reference from "black object" to "white object".
For example, an array object ary is already marked "black".
ary = []
# GC runs, it is marked black
Now an object obj = Object.new is white, if we run this code
ary << obj
# GC has not run since obj got created
Now a black object has a reference to a white object. If no grey objects refer to
obj, then obj will be white at the end of marking phase and reclaimed by
mistake. Collecting living objects is a critical bug, we need to
avoid such blunders.
A write-barrier is invoked every time an object obtains a new reference to a new object. The write-barrier detects when a reference from a black object to a white object is made. When this happens the black object is changed to grey (or grey destination white object). Write barriers solve this type of catastrophic GC bug completely.
This is basic idea of the incremental GC algorithm. As you see, it is not so difficult. Maybe you have question: "why does Ruby not use this simple GC algorithm yet?".
Incremental GC on Ruby 2.2
There is one big issue to implement incremental marking in the Ruby interpreter (CRuby): the lack of write barriers. CRuby does not have enough write barriers.
Generational GC which was implemented in 2.1 also needs write barriers. To introduce generational GC, we invented new technique called "write barrier unprotected objects". It means that we divide all objects into "write barrier protected objects" (protected objects) and "write barrier unprotected objects" (unprotected objects). We can guarantee that all references from protected objects are managed. We can not control references from unprotected objects. Introducing "unprotected object", we can implement a generational GC for Ruby 2.1.
Using unprotected objects, we can also make incremental GC properly:
(1) Color all existing objects white. (2) Color clearly living objects grey, this includes objects on the stack. (3) Pick one grey object, visit each object it references and color it grey. Change the color of the original object to black. Repeat until there are no grey objects left only black and white. This step is done incrementally. (4) Black unprotected objects can point white objects, so scan all objects from unprotected black objects at once. (5) Collect white objects because all living objects are colored black.
By introducing step (4), we can guarantee that there are no living white objects.
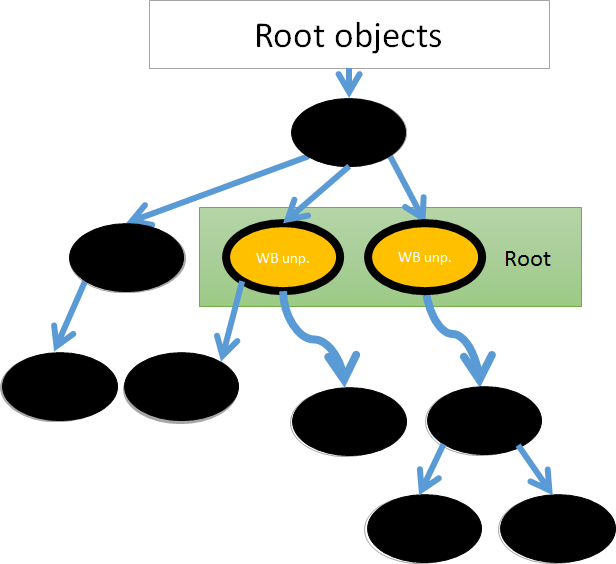 Fig: Rescan from write barrier unprotected (WB unp.) objects at the
end of marking.
Fig: Rescan from write barrier unprotected (WB unp.) objects at the
end of marking.
Unfortunately step (4) can introduce long pause times that we hoped to avoid. However, the pause time is relative to the number of living write barrier unprotected objects. In Ruby language, most of objects are String, Array, Hash, or pure Ruby user defined objects. They are already write barrier protected objects. So long pause time for write barrier unprotected objects does not cause any problem in most practical cases.
We introduced incremental marking for only major GC because nobody complains about pause time of minor GC. Maximum pause time on our incremental GC is shorter than minor GC pause time. If you have no problem on minor GC pause time, you don't need to worry about this major GC pause time.
I also introduced a trick to implement incremental GC for Ruby. We get a set of "black and unprotected" objects. To get such fast GC, we prepare an "unprotected" bitmap which represents which objects are unprotected objects and a separate "marked" bitmap which represents which objects are marked. We can get "black and unprotected" objects using logical product with two bitmaps.
Evaluation of incremental GC pause time
To measure pause times caused by GCs, let's use gc_tracer gem. gc_tracer gem introduces the GC::Tracer module to capture GC related parameters at each GC events. The gc_tracer gem puts each parameters on to the file.
GC events consists of the following events:
- start
- end_mark
- end_sweep
- newobj
- freeobj
- enter
- exit
As I described above, Ruby's GC has two phases: "marking phase" and "sweeping phase". "start" event shows "starting marking phase" and "end_mark" event means "end of marking phase". "end_mark" event also means "starting sweeping phase". Of course, "end_sweep" shows the end of "sweeping phase" and also means the end of one GC process.
The "newobj" and "freeobj" is easy to understand: events at object allocation and object releasing.
We use "enter" and "exit" events to measure pause time. Incremental GC (incremental marking and lazy sweeping) introduces pausing marking and sweeping phase. "enter" event means that: "entering GC related event". and "exit" event means that "exitting GC related event".
The following figure shows the event timing for current incremental GC.

GC events
We can measure the current time (on Linux machines, current times are results of gettimeofday()) for each events. So that we can measure GC pause time using "enter" and "exit" events.
I use ko1-test-app for our pause time benchmark. ko1-test-app is simple rails app written by one of the our hero "Aaron Patterson" for me.
To use gc_tracer, I add a rake rule "test_gc_tracer" like that.
diff --git a/perf.rake b/perf.rake
index f336e33..7f4f1bd 100644
--- a/perf.rake
+++ b/perf.rake
@@ -54,7 +54,7 @@ def do_test_task app
body.close
end
-task :test do
+def test_run
app = Ko1TestApp::Application.instance
app.app
@@ -67,6 +67,22 @@ task :test do
}
end
+task :test do
+ test_run
+end
+
+task :test_gc_tracer do
+ require 'gc_tracer'
+ require 'pp'
+ pp GC.stat
+ file = "log.#{Process.pid}"
+ GC::Tracer.start_logging(file, events: %i(enter exit), gc_stat: false) do
+ test_run
+ end
+ pp GC.stat
+ puts "GC tracer log: #{file}"
+end
+
task :once do
app = Ko1TestApp::Application.instance
app.app
And run bundle exec rake test_gc_tracer KO1TEST_CNT=30000. The value "30000" specified that we will simulate 30,000 requests. We can get a results in a file "log.xxxx" (xxxx is the process id of application). The file should include like that:
type tick major_by gc_by have_finalizer immediate_sweep state
enter 1419489706840147 0 newobj 0 0 sweeping
exit 1419489706840157 0 newobj 0 0 sweeping
enter 1419489706840184 0 newobj 0 0 sweeping
exit 1419489706840195 0 newobj 0 0 sweeping
enter 1419489706840306 0 newobj 0 0 sweeping
exit 1419489706840313 0 newobj 0 0 sweeping
enter 1419489706840612 0 newobj 0 0 sweeping
...
On my environment, there are 1,142,907 lines.
"type" filed means events type and tick means current time (result of gettimeofday(), elapesd time from the epoc in microseconds). We can get GC pause time by this information. Using the first two lines above, we can measure a pause time 10 us (by 1419489706840157 - 1419489706840147).
The following small script shows each pause times.
enter_tick = 0
open(ARGV.shift){|f|
f.each_line{|line|
e, tick, * = line.split(/\s/)
case e
when 'enter'
enter_tick = tick.to_i
when 'exit'
st = tick.to_i - enter_tick
puts st if st > 100 # over 100 us
else
# puts line
end
}
}
There are so many lines, so this script prints pause times over 100us.
The following figure shows the result of this measurement.

We can have 7 huge pause time in generational GC. They should be a pause time by major GC. The maximum pause time is about 15ms (15Kus). However, incremental GC reduces the maximum pause time (around 2ms (2Kus)). Great.
Summary
Ruby 2.2 introduces incremental GC algorithm to achieve shorter pause time due to GC.
Note that incremental GC is not a silver bullet. As I described, incremental GC does not affect "throughput". It means that there is no effect for a response time if the request is too long and causes several major GC. Total time of GC is not reduced with incremental GC.
Please try it on your application on Heroku. Enjoy your hacking!