
Editor’s Note: One of the joys of building Heroku is hearing about the exciting applications our customers are crafting. SHIFT Commerce - a platform helping retailers optimize their e-commerce strategy - is a proud and active user of Heroku in building its technology stack. Today, we’re clearing the stage for Ryan Townsend, CTO of SHIFT, as he provides an overview of SHIFT’s journey into building microservices architecture with the support of Apache Kafka on Heroku.
Software architecture has been a continual debate since software first came into existence. The latest iteration of this long-running discussion is between monoliths and microservices – large self-contained applications vs multiple smaller applications integrated together – but an even bigger question lies under the surface of our architecture philosophy: why does this even matter?
While the architectural choices we make may be hidden away from end-users, they ultimately are affected. Impact can be seen not only in the performance, scalability and reliability of user-facing applications, but also in a much deeper effect on the future of our businesses – the ability to innovate depends on developer productivity, availability of resources, and governance/process overhead. And although there’s no silver-bullet to getting your architecture ‘right’ (sorry!), there is ‘right’ for your business - and that ‘right’ will evolve over time as the company and its needs change. It’s critical we continually ask ourselves: are we doing the right thing? Otherwise, before we know it, our competition is advancing ahead of us.
With the “why” in mind, I’d like to talk a bit more about some of the differences we’ve considered while building our architecture here at SHIFT.
Are Monoliths Such A Bad Thing?
Before we even start to consider whether we should be breaking-down a monolith, we should start with identifying what problems we are trying to solve and not just jump into ripping up the floorboards without an understanding of what a better architecture - perhaps enabled through microservices - actually looks like for you.
There are two aspects of inefficient architecture that are unfairly blamed on monoliths: poorly structured code; and poor scalability. In reality, you absolutely can have a well-factored, maintainable monolithic codebase – Basecamp are a proponent of this - and if we take an honest look at the scale of our applications, very few of us are pushing the boundaries of optimisation or infrastructure.
Bad software architecture isn’t a problem that will magically be solved with microservices; this just shifts the problem from one poorly-structured codebase to many. And as renowned developer Simon Brown astutely states:
“If you can’t build a well-structured monolith, what makes you think microservices is the answer?”
Why Should We Consider Microservices?
Alright, time for some positivity – there are some really great reasons to move to microservices. While we mentioned a few areas that can be false flags for moving away from monolith architecture, if you’re encountering any of these issues - now or in the future - microservices may be for you:
1. Communication Overhead is Hampering Productivity.
Even with the utmost care when companies grow, communication can become an ever-increasing drain on productive development time. If you carve out a whole self-contained area of functionality, you can give teams autonomy and reduce communication/organizational overhead!
We did this with our Order Management Suite, an area with enough complexity and breadth of features to keep a team busy!
2. Overbearing Governance and High-Risk Deployments
Monoliths lump mission-critical features with completely negligible ones. Given SHIFT operates an enterprise-scale platform, we have to manage certain areas very carefully, but we don’t want to allow that to hamper our agility in others.
An example of this is our admin panel, for which outages (planned or otherwise) or bugs have far less severe impact than if carts stopped working on our client’s websites!
3. Language or Infrastructure Limitations
You can probably squeeze out far more scalability from monoliths than you’d expect, and it’s really important you validate you’re not just moving a cost from infrastructure to your expensive development and support engineering teams, but there are times when using other technologies simply makes more sense, for example Node.js or Go are going to be more efficient for slow request handling than Ruby.
At SHIFT, we extracted our integration system, which was making a lot of varied calls, to external HTTP services. Using Node.js for this left Ruby to deal with a more consistent pattern of requests.
What’s the Glue?
No matter how you slice your application, a common principle to succeed with microservices is keeping the resulting applications decoupled from one another. Otherwise, you’re bound to face a litany of downsides. Some see the irony - or humor - in this outcome:
We replaced our monolith with micro services so that every outage could be more like a murder mystery.
— Honest Status Page (@honest_update) October 7, 2015
Requiring real-time, consistent access to functionality or data managed by another service is a recipe for disaster – so we look for clean lines of segregation and pass the rest of the data around asynchronously. This avoids the indirection of one service calling another, that calls another, and so on.
This begs the question: what should live in the middle and help services communicate?
There are a variety of message brokers you could use, such as ActiveMQ and RabbitMQ, but SHIFT chose a managed Apache Kafka service for the following reasons:
- Messages are ordered chronologically and delivery is guaranteed. We wanted all services to have an accurate picture of the system at large.
- Durability, resilience and performance are all incredibly strong. We’re responsible for an enterprise system, it’s paramount we avoid outages, data loss or any form of service degradation.
- Heroku have removed the operational pain. We believe in doing what we’re good at and relying on the expertise of others, where suitable, to keep us lean and agile.
Apache Kafka describes itself as a “distributed commit log” or an “event-stream”, you can think of it as a list of chronological events broken up into multiple streams, known as “topics”.
Your applications can connect into one or more topics, publish new events and/or consume the events sequentially. These events could be simple notifications of actions or they could carry state changes, allowing each service to maintain its own dataset.
There are a whole bunch of other benefits to using an event stream (like Kafka) that Heroku Developer Advocate, Chris Castle, and I covered in our talk at Dreamforce 2017.
What Are Our Steps to Migrating to Kafka-driven Services?
The “big rewrite” is well-known to be something to be avoided if at all possible, so ultimately we need something far less risky.
We arrived at a process for extracting services progressively. This even allows evaluation of whether microservices are the right choice before fully committing because we don’t remove the existing implementation or send production traffic until the final steps.
These are our eight steps:
Step 1: Add Producer Logic to the Monolith
It might surprise you but step 1 is actually adding more code to our monolith! You’ll typically need access to data in your new service, so the first step is to push that into Kafka via a Kafka producer within the monolith.

Step 2: Consume the Stream into the Database
Before we start extracting logic, we’re going to prepare our data store, this will keep our service decoupled from the rest of our ecosystem. This new service is simply going to contain a consumer and the data store initially, allowing local access to state. Depending on your application you may need to backfill the historical data by performing a data migration.

Step 3: Test the Consumer
Validate that your new service is processing the events without errors, and the consumer isn’t getting too far behind on the event stream.
Kafka is designed to handle the consumers getting behind for a period of time – it persists events for a period of time (2-6 weeks on Heroku), so you don’t need to worry about data loss, but it will mean your service has an out-of-date view of the data.
Kafka’s ability to act as a buffer when your system is under high-load is one of it’s great features, so it’s worthwhile understanding and preparing for scenarios where your consumers get behind.
Step 4: Replicate Your Logic
Extract the relevant code from your monolith into the above new application. Test that it works in isolation, by manually executing procedures / API calls. It should be reading from the new data store, without processing any production API calls.
Be wary of functionality that could trigger emails or have other unintended side-effects – you may need to disable some external calls.
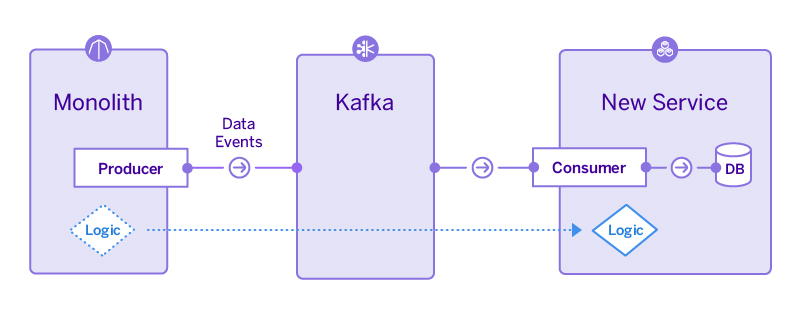
Step 5: Add, Test, and Consume Event Triggers
Add a feature toggle to your monolith which will only send actionable events to the new service for a subset of accounts (obviously this will depend on how your application works, it could be based on users/teams/companies) and implement producers for these events.
You can check these are working by tailing Kafka and ensuring the events you expect are flowing through. Once you’re happy, add consumers to your service which will process these events, executing the relevant procedures within the service.

Step 6: Push Events Back
You may need to communicate back to the monolith, so you’ll need producers in your service and consumers in your monolith to handle this.

Step 7: Test Action Events
Activate the feature toggle for a test account, and test that the application continues to operate as normal.
Step 8: Remove Deprecated Logic From Monolith
Over time, ramp-up the feature toggle to be enabled for more and more accounts., Once all accounts are using the new service, we can remove the feature toggle altogether and make it the default code path.
Finally, we can remove the extracted logic from the monolith. This may have taken a while, but it’s been achieved safely.

Where are SHIFT Today?
We are still on our journey and I expect we’ll have a couple more services extracted this year, but through careful extraction of just a few services, SHIFT are already achieving:
- More regular releases;
- Lower latency on I/O restricted API calls; and
- Prevention of user-facing outages.
My advice to anyone getting started would be to very wary of why you’re considering microservices, don’t just be drawn purely for the shiny technology, be drawn because you have a genuine problem to solve. That said, I recommend trying out Kafka to develop a deeper understanding of what problems it can solve for you. I’d definitely check out the multi-tenant Kafka plans on Heroku - they start from $100/mo, so for the cost of a daily coffee, you can explore the technology with a side project.