A couple months ago, we launched a completely redesigned Heroku status site. Since design is important to us and, we think, to many of you, we're taking a break from our usual blog posts to dig into the Heroku approach to visual product design.
Read on to experience the twists and turns on the way to the final design and let us know in the comments if you want to see more posts like this.
The Premise
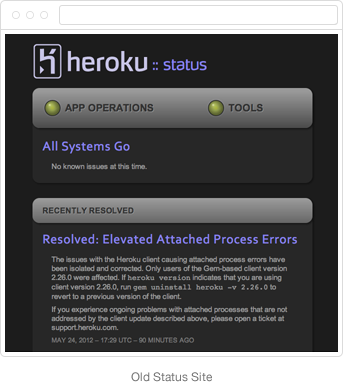
For platform providers, a status site is a way to build trust with your customers, and in some cases, future customers. Heroku is no different. Our existing status site hadn't been updated in over two years and was showing its age. We took this as an opportunity to go back to basics; drafting up user personas and goals. The previous status site was designed around the persona of a Heroku user checking to see if Heroku is working this very second. We realized there is an equally
important persona — a user or prospect trying to understand how reliable the platform is.
Of the many things we could improve, we focused on three primary areas:
-
Status is as much about uptime as it is downtime.
-
We wanted to increase transparency.
-
We needed to streamline the admin experience (which we won't show here).
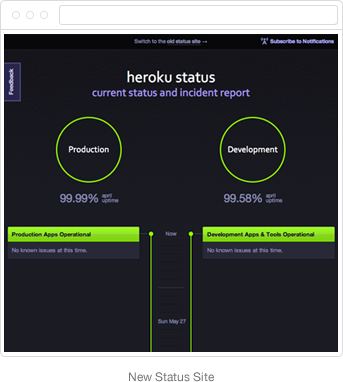
When it came time to start visual designs, we did some research to get a sense of existing solutions and user expectations. After some intensive brainstorming, we came up with the idea of a timeline.
A timeline felt like the perfect device for what we were trying to achieve. Not only does it show downtime and uptime in proportion to one another, but it includes a really key piece of information: time to resolution.
Prototype
It started as just a hypothesis, and we needed to test that hypothesis with real customers as quickly as possible. It's easy to get tied down by visual design and lose focus on what really matters: the product. Instead of spending a lot of time in an image editor like Photoshop making the page look beautiful, we wanted a working prototype with real data from the get-go. Setting aside visual design and best practices, we created a simple Sinatra application using spaghetti code and inline styles, with read-only access to a live database:
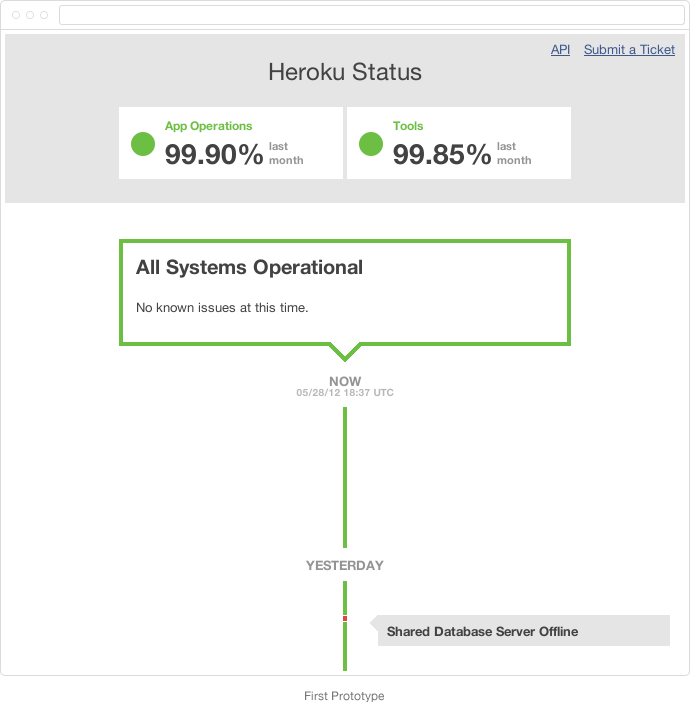
We tested the first pass with our customer advisory board by inviting them to do a 5-minute OpenHallway user study. It was important to set the right expectations (and context) for this survey:
This prototype is not representative of final visuals.
OpenHallway allowed us to capture the screen and audio of our testers and follow alongside them as they explored the site. Incidentally, our first tests had way too many questions and instructions. Eventually we converged on five simple questions:
- What are your first impressions?
- Is it clear what the page is about?
- Does it quickly convey the current platform status?
- Does the page increase or decrease your trust in Heroku?
- How does this site compare to the old status site?
We also added keyboard shortcuts so our testers could simulate outages and scheduled maintenance ('o' and 'm' if you want to follow along).
Mobile
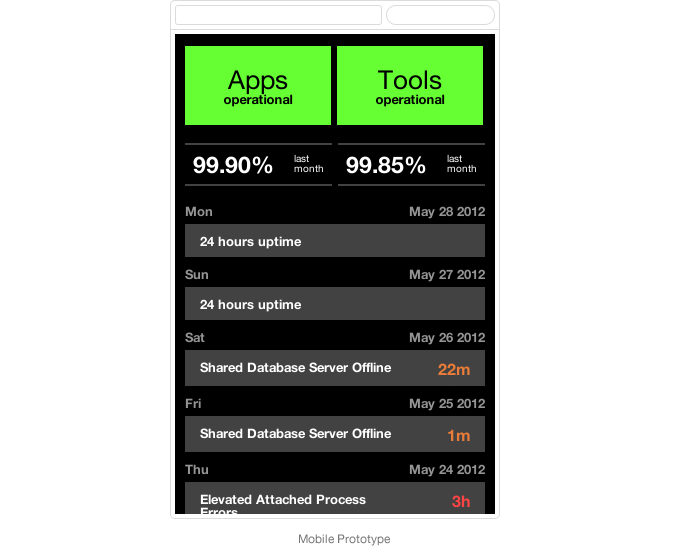
When we reviewed the OpenHallway videos, we noticed a concerning trend; several people commented that there was "too much whitespace". We knew we had taken a risky approach with the timeline and wanted to make sure we weren't committing too early to a design and ignoring actual user needs, so we (incorrectly) interpreted this to mean that the timeline wasn't working.
In an effort to clear ourselves from an arbitrary commitment, we took a step back. Simplify the constraints. Think mobile. We asked ourselves what the status site would look like if we only had 320×480 pixels.
Responsive
Following this promising direction, we created a fully-responsive version that would work for iPhones, iPads, and desktops. We added a little more information in this version; and even more information as you increased screen real estate. But in all these versions, the timeline was gone.
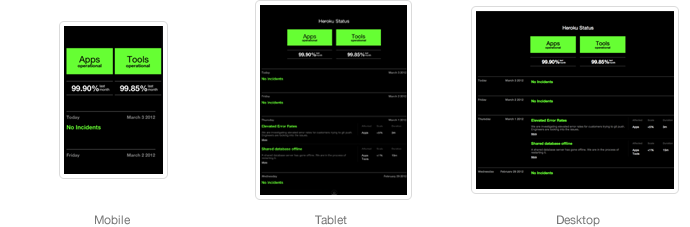
This again looked promising, but it was hardcoded and no longer using live data, so we started wiring it up to live data. Then a surprising thing happened and we realized that the site completely failed to satisfy our first goal of visually conveying uptime as well as downtime. In fact, once we had live data in there, we realized that if 3 consecutive days had something minor happen, like a single shared database server offline that affected significantly less than 1% of our users, it looked like our entire platform was down for 72 hours straight! It was so bad, we knew it didn't even deserve to go through customer validation.
Hybrid
In a last ditch effort to save the responsive design, we tried adding a timeline back into it.
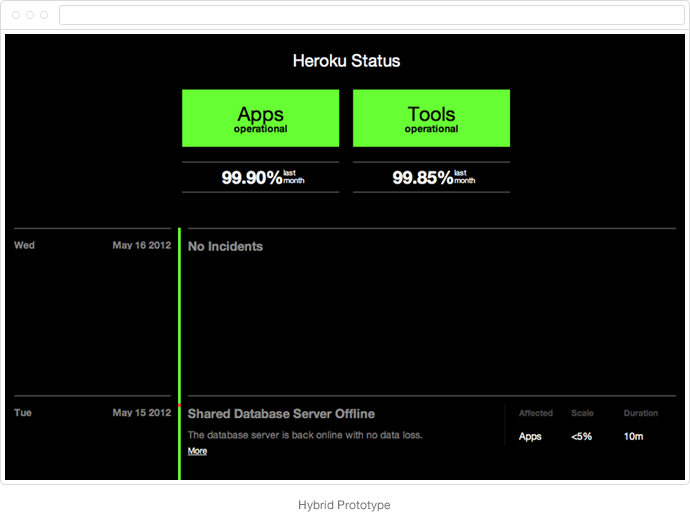
At this point, the design had all of the "features" we needed. It showed a simple list view if you were on an iPhone, added a timeline for anything larger, and progressively added more information as the screen widened. It seemed like a design win, and fit with our new guiding principles of mobile-first and responsive design. Besides, it was fun to resize the screen and see it change!
There was only one problem: we didn't like it. It's hard to describe exactly why; it wasn't clear enough, the emphasis was in the wrong place, the meta data (Affected, Scale, and Duration) was supposed to add value but seemed to distract from the overall site. Design had been replaced by detail.
Bezier
So we took another step back. We took what we had learned so far and re-applied it to our initial gut reaction — the timeline.
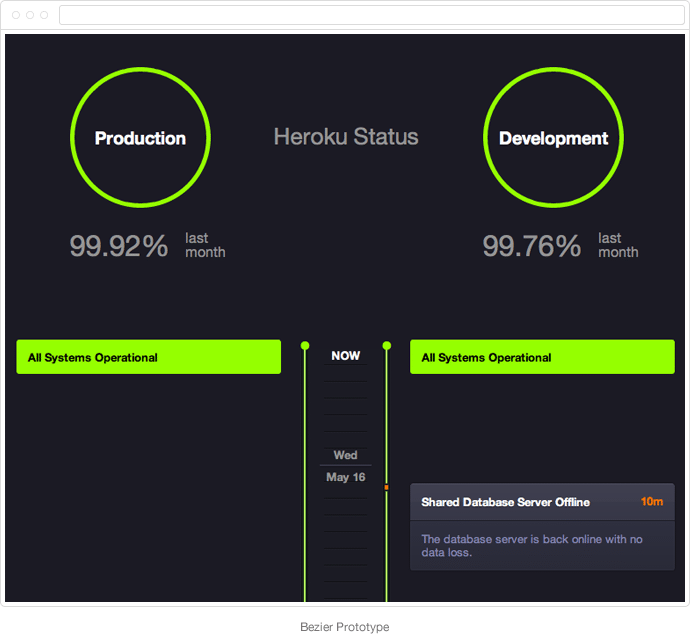
We added some meta information (e.g. duration), but not all of it (e.g. scale). We realized the App Operations / Tools split was very important to our users, but didn't go far enough. Too much counted as App Operations that had no impact on our paying customers, such as the unidling of 1-dyno free apps, or the free shared database offering. We thought about having one status light for each major component of our platform, such as routing or git push, but the complexity didn't add enough value. We then toyed with the idea of splitting based on Production vs Development instead, and it turned out to be such a great fit that we split the timeline into two columns to show it.
By this time, we had already approached all of our customer advisory board and needed more fresh eyes to look at it, so we invited random beta users to do the OpenHallway studies. This time, the comments were different: we had a winner.
We called this version bezier because we intended on having bezier curves to join the incidents with their timeline markers. We didn't get around to implementing them until later in the beta process, but when we did, it really brought the design together, simplifying a lot of hacks we put in place to handle overlapping incidents.
Here's the JSFiddle sandbox we used to get the right shape for the curves. It's not exactly how we implemented it, but it's where we started, and just knowing it was feasible let us move on with the design.
Beta and Release
All of the designs above were intended as throwaways since they were prototypes solely designed to be validated with customers. But as sometimes happens, we got such great response from the last design, that we decided to go into beta with the design largely unchanged.
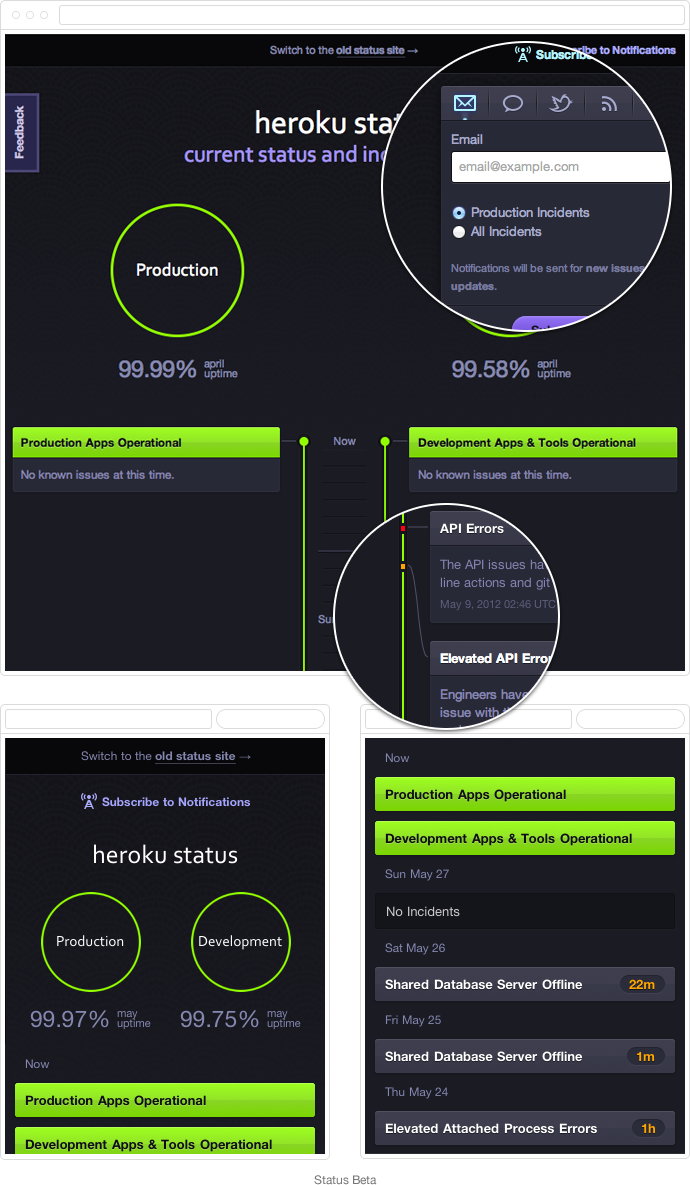
We're happy with the final design; we use it internally and even have it up on a big screen in our office. But like anything we build, this is a perpetual work-in-progress. The new status site provides more value than the previous one, but we're going to continue iterating and improving, so keep the feedback coming!